

The previous article showed how inferential systems reshape decision chains once they become embedded in operational environments. That transformation revealed a deeper truth: the fragility introduced by these systems is not a technical issue. It is a structural issue. Institutions continue to evaluate AI using categories, tools, and frameworks designed for deterministic architectures—systems whose behavior is predictable, proportional, and transparent. Inferential systems do not behave this way.
This fourth article examines why existing governance mechanisms break down when applied to inferential architectures. It explores the gap created by outdated conceptual categories, static evaluation tools, performance-oriented procurement, and vendor documentation that obscures dependencies and failure modes. The central argument is simple: the problem is not the model. It is the institution’s inability to see what the model changes.
Conceptual Categories That No Longer Map the System
Oversight practices rely on predefined conceptual structures—interpretive lenses that describe what a system is, how it behaves, and which forms of performance are considered acceptable. These structures guide risk interpretation, shape compliance assessments, and justify operational decisions. When the underlying categories are misaligned, every evaluative process built upon them inherits the distortion.
The categories commonly applied to AI systems—accuracy, reliability, auditability, compliance—were created for architectures whose internal logic remains stable across time. They presume consistent behavior, predictable outputs, and a direct relationship between model performance and an underlying ground truth. Inferential systems diverge from these premises because their internal representations reorganize, their baselines shift, and their signal weighting adapts to subtle changes in the environment.
The mismatch becomes evident when evaluators attempt to interpret model behavior through categories that no longer correspond to the system’s dynamics. A performance metric may suggest stability while internal representations are restructuring. An audit may confirm procedural alignment while the model adjusts its weighting of signals in ways the audit cannot register. A reliability score may appear strong while the model amplifies or suppresses patterns that remain outside the evaluator’s awareness.
This divergence produces epistemic compression: the complexity of the model is reduced to a narrow set of metrics that cannot capture its internal transformations. The resulting picture conveys stability, yet it reflects only the interpretive frame rather than the system’s actual behavior.
The issue does not arise from flawed categories; it arises from categories rooted in a previous era of system design.
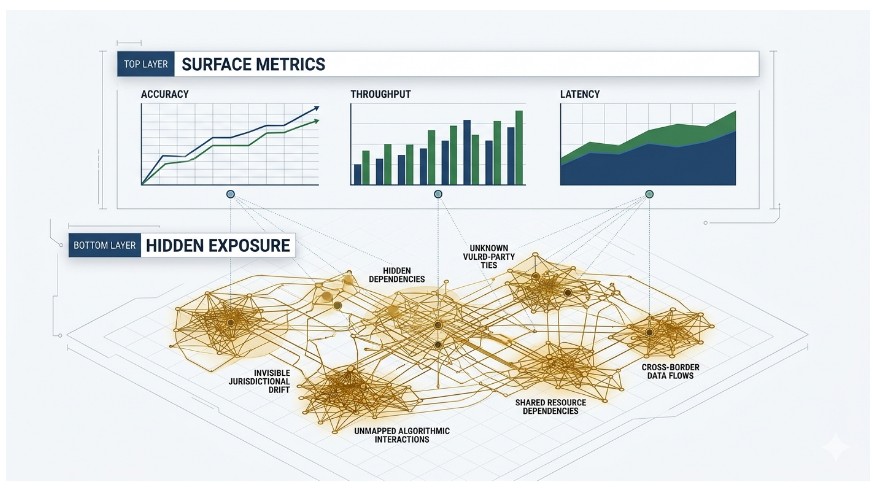
Models Built for Static Assumptions
Legacy governance tools were created for systems whose behavior remains consistent across time. They rely on linearity, proportionality, transparency, and stability—principles that presume predictable internal logic and uniform responses to changing conditions. Inferential architectures diverge from these premises because their internal representations shift, their weighting of signals adapts, and their operational footprint evolves continuously.
Linearity erodes when small variations in input distributions trigger substantial reorganizations in representational space. Proportionality weakens as minor perturbations propagate across workflows. Transparency diminishes because internal mechanisms cannot be accessed or interpreted through conventional evaluative tools. Stability fades as the model restructures itself in response to new data and shifting environments.
Despite these transformations, evaluative practices remain anchored to instruments built for static systems. Periodic reviews attempt to capture behavior that evolves in continuous time. Documentation is examined as if it could reflect internal reorganization. Risk assessments rely on historical performance even though past behavior offers limited insight into future dynamics within non‑stationary environments.
These practices operate through discrete intervals—reviews, audits, compliance checks—while inferential systems evolve without interruption. The temporal gap ensures that evaluative processes trail behind the system they aim to supervise. By the time a review is completed, internal logic may have reorganized repeatedly in response to new conditions.
The result is a snapshot of a system that no longer exists. Evaluators believe they are engaging with the current model, yet they are interacting with a past configuration whose internal dynamics have already shifted.
The Failure of Traditional Frameworks
Governance models such as NIST, ISO, and compliance‑driven standards were built for deterministic architectures. They operate on the premise that behavior can be documented, that failure modes can be enumerated, and that risk can be captured through predefined categories. Inferential systems exceed these premises. Their internal logic reorganizes, their representational baselines drift, and their dependencies redistribute across workflows in ways that cannot be captured by static oversight tools.
The limitation lies in the conceptual perimeter these models establish. They were created to interpret systems whose internal dynamics remain stable. They cannot register how inferential layers restructure themselves under operational pressure, how small signals propagate non‑linearly, or how operator adaptation reshapes behavioral patterns. These dynamics emerge only in real environments, where stress reveals fragilities that no certification process can anticipate.
This structural mismatch produces a secondary exposure. Once a system is certified, institutions often treat compliance as evidence of safety. Operational teams rely on documentation that reflects past configurations, reinforcing the perception that certification captures the system’s full behavior. Procedural validation becomes a substitute for active interpretation. The certification reflects only a narrow slice of the system’s behavior, yet it is frequently treated as a comprehensive assessment. The result is a form of institutional self‑assurance that obscures how the model alters decision chains and redistributes operational authority.
These governance tools perceive only the dimensions they were designed to evaluate. Everything outside that evaluative field disappears from view. Oversight bodies interpret stability through instruments that cannot detect the dynamics that matter most. A model may satisfy every compliance requirement and still reorganize its internal logic in ways that destabilize workflows. A system may be labeled “robust” while generating structural effects that remain entirely outside the scope of the certification.
Institutions often conclude that the system is safe because the certification indicates safety. But the certification is oriented toward a static representation of the system, not toward the evolving dynamics that shape real‑world behavior. The evaluative lens points in the wrong direction.
Micro‑Case: FAA NOTAM Outage (2023)
In January 2023, the FAA’s NOTAM system—treated as a mature and stable architecture—experienced a nationwide outage that halted more than 11,000 flights across the United States. The system had passed every review and was considered structurally reliable. Under load conditions, a corrupted file propagated through interconnected components, triggering a cascade that evaluators could not anticipate. The tools used to assess stability were built for deterministic behavior and could not register how internal processes interacted when conditions shifted. The event revealed a critical gap: the system behaved differently under stress than in the environments used to certify it.i
Performance-Oriented Procurement: The Hidden Accelerator
Acquisition practices shape how AI systems enter operational environments. These practices prioritize metrics such as accuracy, speed, and efficiency because they are simple to compare, easy to justify, and directly tied to competitive outcomes. Procurement teams rely on these metrics to structure comparative evaluations, reinforcing the perception that performance captures the system’s full behavior. Developers optimize for these metrics, aligning their objectives with the criteria that determine market success.
This alignment produces objective‑function distortion: models are tuned to excel in controlled benchmarks while remaining vulnerable in environments where conditions shift continuously. Performance becomes the dominant signal, while structural stability receives little attention. As a result, the acquisition ecosystem rewards systems that demonstrate strong benchmark results and discourages transparency about internal dependencies, drift behavior, or fragilities that emerge only under stress.
The absence of incentives to disclose internal dynamics reinforces opacity. Developers focus on metrics that influence purchasing decisions, and evaluators rarely request deeper documentation because it does not affect comparative scoring. In procurement reviews, committees often rely on standardized templates that emphasize measurable outputs over internal behavior. The acquisition process becomes a mechanism that selects for systems optimized to perform well in testing rather than systems capable of maintaining coherence in real‑world conditions.
These dynamic produces procurement‑driven exposure. Systems that appear reliable in controlled environments may reorganize their internal logic during operational events. Models that achieve high accuracy in benchmarks may amplify subtle patterns absent from the training data. Performance metrics may conceal structural effects that reshape workflows once the system is deployed.
Evaluators often conclude they are acquiring high‑performance technology. In practice, they are acquiring systems optimized to succeed in tests that do not reflect the environments in which the systems will operate.
Documentation That Obscures Dependencies
Technical material prepared for procurement settings focuses on performance claims, feature summaries, and compliance statements. It portrays the system as a fixed construct with clear boundaries and predictable behavior. What remains outside this portrayal is the set of conditions that shape how the model behaves once deployed—conditions that shift over time and reshape the model’s internal activity under pressure.
These conditions span several layers. Some originate in how data is gathered and transformed, or in how different components of the model interact. Others emerge when the system is inserted into real workflows, where escalation paths, task distribution, and human–machine interaction begin to reshape behavior. Additional influences arise from how operators adjust their routines, gradually altering the model’s inputs. Broader forces also play a role, including the origin of data, supply chain routing, and the pathways through which cloud services move information. Each layer contributes to how the model responds when circumstances change, yet these dynamics rarely appear in procurement materials.
The omission is structural. These relationships evolve, resist simple categorization, and often become visible only when the system is exposed to real‑world stress. Decision makers rely on a narrow picture that does not show how internal logic reorganizes, how sensitivity thresholds shift, or how small signals travel through interconnected components. Review teams often interpret documentation as a stable reference point, reinforcing the assumption that the system’s internal behavior aligns with its procurement‑level description. The result is a form of opacity: the interactions that matter most remain outside the frame.
Performance tables may highlight benchmark results without showing how the model adjusts its weighting of inputs over time. Architectural diagrams may list modules without clarifying which external sources shape their behavior. Compliance documents may outline controls without revealing how decision pathways change once the system is embedded in daily activity. Each artifact captures a slice of the system, but none convey how the system evolves after deployment.
Readers often assume they have a complete view because the material appears thorough. In practice, it reflects the system as presented for acquisition, not the system as it behaves in environments where conditions shift continuously. Exposure accumulates in the space between these two versions.
The Institutional Blind Spot as a Strategic Risk
Complex systems are interpreted through conceptual structures that were created for stable architectures. These structures rely on categories that no longer map dynamic behavior, oversight tools calibrated for deterministic environments, governance models unable to register internal reorganization, procurement processes that elevate performance over transparency, and documentation that presents only a narrow slice of operational reality. Together, they form an evaluative lens that excludes the dynamics that matter most.
This lens generates a deep epistemic gap. Critical transformations remain outside the field of view: internal logic reshapes itself, workflows shift, operator behavior adapts, and signal distributions evolve in ways that become visible only under real‑world pressure. Fragilities that emerge in operational environments remain undetected because the interpretive apparatus was never designed to perceive them.
The gap produces strategic exposure. Operational stability becomes vulnerable to behaviors that cannot be explained or traced. When a model behaves unpredictably, the organization lacks the means to identify the underlying cause. When a decision chain collapses, it cannot determine whether the origin lies in technical dynamics, structural interactions, or oversight limitations. When a failure propagates through workflows, the source remains opaque.
The organization often assumes it is directing the system. In practice, the system is reshaping the organization. The interpretive frame remains fixed while the operational environment evolves, creating a divergence between perceived control and actual dynamics. That divergence is the blind spot—and it is where strategic risk accumulates.
Transition to Part V: Mapping Exposure
The dynamics explored in this article show that failures in AI‑driven environments arise from architectures built for systems whose behavior remains stable across time. These architectures cannot interpret models whose internal logic evolves, reorganizes, and interacts with operational conditions in non‑linear ways. The blind spot is structural: evaluators lack the conceptual tools needed to perceive how the model reshapes its environment.
This gap has direct operational consequences. When inferential systems restructure workflows, redistribute authority, or alter the weighting of signals, evaluators lose visibility into their own exposure. They cannot determine where exposure accumulates, how it propagates, or which dependencies become critical under stress. The result is a form of structural opacity that no audit, review, or performance metric can resolve.
The next article in this series addresses this challenge directly. It introduces a method for understanding how exposure emerges from the interaction between models and critical infrastructure, and how evaluators can regain visibility over the systems they rely on. Part V outlines a structural approach for mapping exposure—one that reveals not only what the model does, but what the model changes.
Sources
i https://www.reuters.com/world/us/airlines-expect-us-operations-rebound-thursday-faa-investigates-outage-2023-01-12/#:~:text=WASHINGTON%2FCHICAGO%2C%20Jan%2012%20(,airline%20operations%20returned%20to%20normal. https://apnews.com/federal-aviation-administration-general-news-5805d15f520de8eadf52abb7b170487f
